Page Caching with MySQL and PHP
I briefly mentioned about the server "caching" pages between MySQL and PHP via the CMS I employ. So what is this caching thing? Well, it's actually a pretty cool and really smart way of handling data. In the old days, when most pages were static and coded by hand, a user would visit a website, their browser would request the page from the server, the server would return the page, it would get downloaded, and the browser would display it to the user.
This worked well for a long time as few sites had frequently changing content and almost all pages were static. Once the web got more advanced and more news sites and other "dynamic" content started popping up, it became apparent that the old management schemes wouldn't be sufficient. Maintaining a site with any reasonable number of pages gets very difficult, especially as you add more and more content. Take for example a news site that includes a link to a monthly archive on each page. For the first few months, everything is pretty simple, but even four or five months in, you might be editing upwards of 150 pages with each coming month! That's absolute craziness and a waste of your time.
The solution? Keep your website under five pages. Just kidding. So how do you support dynamic content without the personal overhead? First, let's define "dynamic" content. Dynamic pages are those created on the fly by virtue of a content management system. CMSs are great because they allow the rapid addition, modification, and deletion of content from a website with only a few clicks. No more opening the HTML code and tediously copying tables and pasting the new data in place. There are commercial CMS packages that you can purchase, but I recommend one of the free open source solutions. Or, you could be really cool and roll your own!
To get back on topic, that sounds cool, but what does that have to do with caching? Old sites basically had the cache thing down pat. Their pages were static and required very little computation overhead from the server. All it had to do was say "Here! Found it!" and return the page. By contrast, SQL and PHP based systems have to pull the information from the database and generate the markup code EVERY time someone asks for it. That's like writing the same report over and over again: from scratch.
Caching is Your Friend
At the heart of caching is an inherent laziness. I like to call it working smart. Caching a page just means that the first time someone asks for the page, I create it, then store that pre-processed version. When the next person comes along, I just pull that pre-processed page off of my desk and hand it off, a nice throw back to the good ole' days of static web pages and animated gifs. This caching reduces the computational overhead (over time) since we can rely on work we did in the past. The only catch is that we have to be concious of deleting the cached pages every time a change is made.
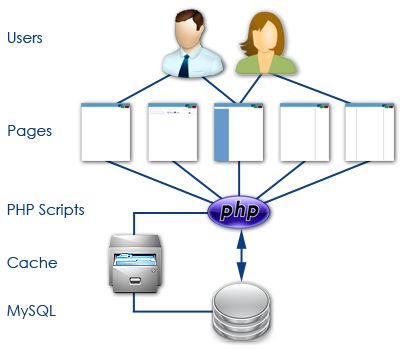
So our flow looks more like that above. User requests a page, PHP scripts say "Hey! Do you have a cached version?" If not, the SQL database is polled to compile the page, and it's then stored on the server as a cached file. Once the next user comes along, the PHP script can pull the pre-processed page off the server and quickly display it to the user.
Show me the code!
This is the basic format of the page caching utility used by the news section at DanShope.com. Since there is one script that is accessed to display every single news article we must have some way of indentifying which page to render, which we pass as "id". The page first looks to see if a cached version of itself exists. If a file does exist, then it reads in the cached page and displays it, then exits. No more work needs to be done by the script, since we are relying on previously compiled markup.
If the cached file doesn't exist, we must create it. This is where the ob_start() function call comes in. It's simply a PHP function that freezes all data we write out into a buffer so that we can access it later. After the page is displayed the PHP script at the bottom simply gets all of the information out of the buffer and writes it to disk. Voila, you have a cached page.
<?php
....
$cacheFile=$_SERVER['DOCUMENT_ROOT']."/cache/id".$_GET["id"].".html";
if (file_exists($cacheFile)) //we can read this cache file back reduce database load
{
header("Content-Type: text/html");
readfile($cacheFile);
exit;
} else {
ob_start(); //start buffering so we can cache for future accesses
}
...
?>
<html><body>
DO THE HTML RENDERING HERE
</body></html>
<?php
// get the buffer
$buffer = ob_get_contents();
// end output buffering, the buffer content
// is sent to the client
ob_end_flush();
// now we create the cache file
$fp = fopen($cacheFile, "w");
fwrite($fp, $buffer);
fclose($fp);
?>
There are some other function calls going on here to handle the file creation and reading, but you can copy and paste this code without worrying about how they work. The code is fairly robust and I haven't had any problems with it so far. One thing I did add is a clause that allows me to delete the cached file if the page has changed.
Let's dig a little deeper...
Speed is one constraint here, but mostly we are concerned with sparing precious resources. There's a cost associated with maintaining a server and supplying content to users, and we want to minimize that cost as much as possible. There are other methods of caching around - your computer stores things in RAM (dynamic memory) that you access frequently so it can speed up retrieval processes. Your browser can cache content you access often so that it can show it to you sooner without fetching it repeatedly. This is called client-side caching, because you, the client, are storing the data. When the website you are accessing stores the content, it is called server-side caching.
Another important aspect of most caching strategies is the concept of "fresh" data. Caching is all well and good, but if you are caching (on the client side) a page that might change in the future, you probably want to update it at some point. Therefore, cached content can have an expiration date, much like that gallon of milk in your refrigerator. If it's been a long time since a page has been fetched, it might be a good idea to revisit the page and see if anything is new. Some more intelligent schemes can check if the page has changed without downloading the whole thing. All of these management strategies are designed to give users a quick and fluid experience while keeping server operation costs down. Everyone's a winner!
Labels: cache, CMS, Content Management, MySQL, PHP
This entry was posted
on Saturday, November 22, 2008 at 10:55 PM.
![]()
 Subscribe to DanShope.com
Subscribe to DanShope.com